
AIs understand any data in numeric form.
And this truth answers the title's question, "It understands them as numeric form".
Then, how are they changed into numbers?
You must wonder about the rule.
The method is 'embedding'.
There are several embedding ways. I will deal with basic methods to recent methods including graphical ways.
Traditional embedding way
There are several methods for text embedding, but in this post, let's deal only with the 'Word2Vec' method which is the simplest embedding tool.
Word2Vec's goal is to predict a word given the surrounding words of the target.
For example, if the model is given the following sentence, it should infer the answer as 'banana' by deciding all the words into the appropriate vectors.
The monkey is peeling a [ ] on a tree.
The model is constituted of three neural layers.
Each for input, inference, and output.
First, we assign every word an integer index.
Then, we give CONTEXT WORDS as input which is the surrounding words around the target word as a form of ONE-HOT ENCODDING. As each word has an integer index, it is easy to present a word in a one-hot encoding way.
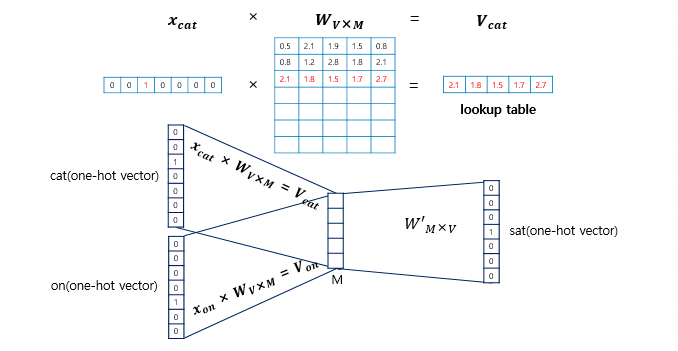
And finally, the overall model's architecture is as follows.
reference: https://www.slideshare.net/slideshow/wordembeddingspptx/255485293
Word_Embeddings.pptx
Word_Embeddings.pptx - Download as a PDF or view online for free
www.slideshare.net
Enhanced embedding methods
Recent embedding models are trained with profound text datasets,
In the case of one pioneer company, Jina detailed the training process in their publishing.
https://arxiv.org/abs/2307.11224
However, when I applied the document embedding API to my private NEWS GPT service, it did not work as expected. Most of the retrieved documents for referencing seemed empirically irrelevant to the user's query.
The solution was chunking for that case, but at that time, I realized the current embedding method is not a super tool yet.
Since I am most interested in the knowledge graph embedding method, let us dive into it.
Knowledge graph embedding (KGE)
A graph is a form of information made up of nodes and vertex.
The graph is a tool to effectively display the information for specific tasks like recommendation and vector search.
If the task is about houses, the graph can efficiently have important information, such as linking a house to regions, size boundary, house category, empty or not, etc. Besides, the non-graph way is less scalable as it needs to contain noise and useless data in official documents related to houses and social community posts.
Please refer to the below link for further understanding of KGE. I will write about this topic later.
https://zzaebok.github.io/machine_learning/knowledge_graph/kge/
Remaining Curiosity about KGE
Challenge: Extracting the higher-level concept or concept that is missing in the given document
An overall feeling or genre is not explicit in a movie's synopsis. For example, in the text "In an abandoned house, unknown sounds come out every night...", humans can easily guess this movie is in the horror genre but that 'horror' word does not explicitly exist.
Development: This can be the enhancement of language models.
Queries can be something like this. "What is the main concern of the US president?". In KGE, the relevance can be described as (Joe Biden, is, the US president) and (Joe Biden, concerns, the relation between the US and China).
This is similar to the language models' behavior that predicts the following words given in the prior sentence.
By the way, the advantage of KGE is in the visual illustration as this method is similar to MINDMAP.
It is unclear that processing into a vector is necessary, but maintaining the text dataset in a graph would be an interesting project.
In the next post, I will cover the traditional embedding methods more diverse and deeply.
And I would love every comments for further DISCUSSION and checking ERRORs in my post ❤️🔥
'🤖 인공지능' 카테고리의 다른 글
| Make AI say everything about Golden Bridge without prompt engineering (0) | 2024.06.20 |
|---|---|
| [데이터 엔지니어링] ETA(Estimated Time of Arrival) 모델 설계 (0) | 2024.04.13 |
| [DVC] Data Version Control 서비스 비교 (0) | 2024.03.10 |
| [부스트코스] 숨어있는 결측치 처리 방법 (결측치가 없었는데요, 있었습니다.) (0) | 2024.01.27 |
| [2023 모두콘 후기] 10점 만점에 7점? 흥미롭고 동기부여가 됐던 발표 세션들 (발표 세미나-2) (0) | 2023.12.25 |